
Eletään ”informaatioaikakautta”. Tästä esimerkkinä vanhan paperitehtaan tiloihin tulee Google. Paperi muuttuu binääriseksi. Dataa – tietoa – on numeraalisessa ja ei-numeraalisessa muodossa, josta pitäisi päätellä jotain. Katsot mihin tahansa, ympärilläsi on vuorittain – gigatavuja – dataa. On vuosikatsauksia, neljännesvuosikatsauksia, asiat esitetään tilastoin ja graffein, on tilastoja jos mistäkin. Mitä datasta pitäisi päätellä? Kuinka dataa analysoidaan? Mitä johtopäätöksiä tästä tehdään? Vastaus lyhyesti: varmista datan oikeellisuus, analysoi, tulkitse ja omaksu.
Taulukossa 1 on kuvattu suunnitellun kokeen (DOE) tuoma hyöty. Käytännössä tämä tarkoittaa dramaattista kehitysnopeuden kasvua. Vasemmassa laidassa tutkittavien tekijöiden määrä, keskellä perinteisesti tehtävien kokeiden määrä ja oikealla DOE tekniikalla tehtävien kokeiden määrä.

Numeronaivius – kertaus
Viimekädessä kaiken uuden tiedon – parannuksen – luomisessa on kysymys vertaamisesta, joko menneessä tapahtunut tai aiheutettu muutos. Tuotekehityksessä ja tuotannossa käytetään yleisesti hyvin kallista ja tehotonta yksimuuttuja vertailua DoE:n sijaa. Mitä vertailu taktiikka sinä käytät? Hallitsetko monimuuttujatekniikat – DOE?
Onko sinulla aikaa tehdä 2000 testiä vai 12? Katso taulukko 1, jossa on esitetty DOE:n tuoma hyöty. Vertailujen tuloksena syntyy dataa – tilastoja. Maailma käyttäytyy nykytieteen tuntemuksen mukaisesti niin, että vain harva data pitää sisällään informaatiota – signaalia.

Signaalia on vain harvassa yksittäisessä datassa (n. 2 %), mutta kaikki data sisältää kohinaa (n. 98 %). Seuraus tästä realiteetista on, että milloinkaan ei voida tehdä järkeviä päätöksiä, ennen kuin suodatetaan pois KOHINA.
Ensisijainen työkalu tässä suodatuksessa on yksinkertainen SPC-kortti, joka tunnetaan nimellä I-mR eli Individual-kortti. Jos dataa on paljon, kohinaa Ensisijainen työkalu tässä suodatuksessa on yksinkertainen SPC-kortti, joka tunnetaan nimellä I-mR eli Individual-kortti. Jos dataa on paljon, kohinaa voidaan suodattaa pois laskemalla keskiarvoja (x-R -kortti). Keskiarvot vaihtelevat vähemmän kuin yksittäiset arvot. Tätä aihetta käsiteltiin edellisessä artikkelissa – Mitä pitäisi ymmärtää datasta – tilastoista? – OSA II.
Datan – tiedon – kerääminen
Samalla kun kohinan suodattaminen on perusta kaikille datan analyyseille, on olemassa vielä kaksi erilaista ympäristöä, jossa datan analyysi tapahtuu.
- Data on peräisin kokeista tai erityistutkimuksista – Experimental Studies – Tehdään dataa
- Data on peräisin jokin toiminnon sivutuotteena – Obsernational Studies – Kerätään dataa
Nämä kaksi eri ympäristöä data-analyysissä aiheuttavat kaksi erilaista ”asennetta” itse analyysiin. Ero on perustavaa laatua oleva oikealle datan ymmärtämiselle ja tekniikoiden käytölle. Kysymys on: Kokeellisista tutkimuksista ja havainnointitutkimuksista ja niiden analysoinnista (Conformity Data Analysis – CDA ja Exploratory Data Analysis – EDA).
Lean Six Sigma DMAIC-prosessi on huippuunsa viritetty prosessi, joka ohjaa tekijänsä parannusvaiheessa kokeellisesti tehtävään datan luomiseen ja sen analysointiin.

Kokeellisesti kerättyä dataa käytetään, kun tehdään tutkimuksia ja parannuksia. Tavallisesti verrataan kahta tai useampaa olosuhdetta määrittääksesi, mikä yhdistelmä on jossain mielessä parempi. Joukko havaintoja kerätään kussakin olosuhteessa ja nämä havainnot muodostavat perustan vertailulle.
Koska jokainen olosuhde tavallisesti vaatii erityisasetukset ja erityispiirteet per ajo, rajoitetaan se yleensä näytemäärän keräyksessä minimiin tehtäessä vertailuja (analyysiä).
Rajattu näytemäärä vaikuttaa tapaan, jolla analysoidaan dataa. Näytemäärä yleensä maksaa. Niinpä yritetään rajata näytemäärän pienimmäksi mahdolliseksi, jolla haluttu muutos voidaan havaita. Kokeellisessa tutkimuksessa käytetään aina äärellistä määrää dataa suorittaakseen kertaluontoista analyysiä, kun katsotaan eroja, jotka yritettiin luoda koekeskiarvoihin. Jotta analyysi olisi herkkä, hyväksytään tavallisesti kohtuullisen riski (5 %) havaita sattumaa.

Datan syntyessä operaation sivutuotteena, (siis normaalia tuotantodataa, seurantadataa) prosessit toimivat tavallisesti jossain määrin vakiotilanteessa. Tällöin halutaan tietää tapahtuiko, vai ei, jokin suunnittelematon muutos. Eli verrataan nykyistä tulosta aikaisempiin. Tämä on täysin eri kysymys kuin kokeessa! Tässä tilanteessa on vain yksi olosuhde (kokeessa vähintään kaksi).
Havaintotutkimuksessa ei olla katsomassa eroa, jonka ajatellaan olevan, vaan kysytään, onko tapahtunut tuntematon muutos (vrt. kokeessa tunnettu muutos). Jos muutos on syntynyt, voidaan lähetä selvittämään, mistä se johtuu.
Ennen kuin julistetaan muutos, halutaan olla kohtuullisen varmoja, että muutos on tapahtunut. Tämä tekee analyysitavasta konservatiivisemman. Kaiken lisäksi muutos voi tapahtua minä hetkenä tahansa, tämä kysymys on kysyttävä jatkuvasti prosessilta aina, kun uusi data tulee operaatiosta ”käyrälle”. Tämä on jatkuvaa vertaamista aikaisempaan.
Perustavaa laatua oleva ero kokeellisessa tutkimuksessa ja havaintotutkimuksessa on käyttää eri tekniikoita ja erilaisia lähestymistapoja analyysiin. Jos et voi ymmärtää tätä eroa, voit päätyä virheellisiin johtopäätöksiin ja sopimattomiin analyyseihin. Voi olla, että sinusta tulee numeronaivi.
Luotettavuusvälit, hypoteesitestit, regressiotekniikat ja tietysti DoE on suunniteltu ”puristamaan” viimeinenkin pisara kiinteästä ja äärellisestä määrästä koedataa. Todennäköisyysmallit ja kriittiset arvot on tarkoitettu ”terävöittämään” analyysejä niin, että kohtuullisen suurta signaalia ei hukata. Lean Six Sigma -prosessi yhdistää edellä mainitut tilastolliset työkalut dynaamiseksi kokonaisuudeksi, jonka avulla pienennetään signaalin menetysriskiä ja toisaalta nostetaan onnistumistodennäköisyyttä.
Toisaalta vastakohtana koedatalle on prosessin käyttäytymistä kuvaavat käyrät (SPC kortit), jotka erottelevat potentiaalisen signaalin todennäköisestä kohinasta käyttämällä geneeristä (kaiken kattavaa) ja kiinteää kolme-sigma rajaa analyysipohjana. SPC-kortit ja niihin liittyvät menettelyt ja tekniikat ovat ainoat jatkuvan operaation/tuotantodatan analyysimenetelmät. Kaiken lisäksi SPC sallii suorittaa tämän erottelun käyttämällä dataa, joka on saatu olemassa olevasta prosessin tilasta ilman että tarvitsee tehdä mitään erityisiä kokeita tai tutkimuksia.
Huom! Käytännössä tämä siis tarkoittaa, että tuotantodataan voidaan käyttää vain SPC-kortteja ja kokeellisesti tuotettuun dataan muita analyysimenetelmiä.
Tulkitse ja omaksu
Analyysitulosten tulkitsemisen helpottamiseksi on luotu joukko ohjelmia, joiden tarkoituksena on visualisoida datajoukko sekä tuottaa yhteenveto datasta. Useissa tilastollisissa ohjelmissa tämä esitetään P-arvona (Probability Value), jolla kuvataan todennäköisyyttä, jolla havaittu muutos voi olla sattuman aikaan saamaa. Perinteisesti ihmiset vain tuijottavat lukujoukkoa osaamatta ”käsitellä” sitä luettavammaksi, saati jalostaa sitä ja luoda todennäköisyysperusteisia johtopäätöksiä.
Käyttökelpoisia konsepteja tuotantodatan analysointiin ovat mm. histogrammi tunnuslukuineen sekä individual ja muuttuvan liukuvälin kortti (I-mR).
Kuvissa 5-8 on käytetty I-mR -korttia allaolevan datajoukon, taulukko 2, analysointiin.
Taulukossa 2 on tuotantodataa neljästä eri tilanteesta. Tavoite on saavuttaa tulos 26. Kuinka on onnistuttu? Tulkitsetko taulukoita?
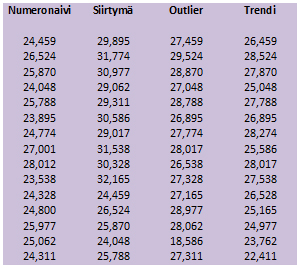

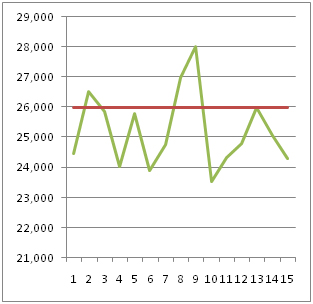
Yllä olevissa kuvissa 3 ja 4 oleviin tulostavoite poikkeamiin numeronaivihenkilö löytää aina selityksen. Mitä isompi ja arvovaltaisempi henkilö pomo kysyy, sitä vakuuttavampi selvitys.
Kuvassa 5 on I-kortilla luotu data-analyysi edellä esitetyistä tuotantodatasta. Data on vain kohinaa, rutiinivaihtelu. Poikkeamille tavoitteista ei löydy yhtä erityistä syytä. Poikkeamien selvittäminen kuluttaa resursseja turhaan ja johtaa suurempiin ongelmiin.

Kuvassa 6 on I-kortilla luotu data-analyysi edellä esitetyistä tuotantodatasta. Data on havaittavissa signaali rutiinivaihtelun lisäksi. Poikkeamalle, tässä siirtymälle, on löydettävissä selitys. Mikäli se löytyy, tieto prosessista lisääntyy.

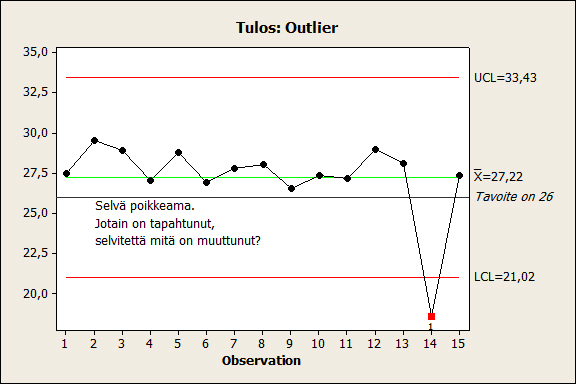
Kuvassa 7 on I-kortilla luotu data-analyysi edellä esitetyistä tuotantodatasta. Data on havaittavissa signaali rutiinivaihtelun lisäksi. Poikkeamalle, tässä yksitäinen piste, on löydettävissä selitys. Mikäli se löytyy, tieto prosessista lisääntyy.
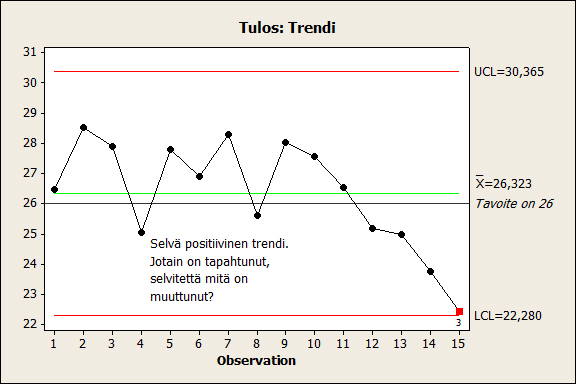
Kuvassa 8 on I-kortilla luotu data-analyysi edellä esitetyistä tuotantodatasta. Data on havaittavissa signaali rutiinivaihtelun lisäksi. Poikkeamille, tässä trendi, on löydettävissä selitys. Mikäli se löytyy, tieto prosessista lisääntyy.
Omaksu
Analyysin ja tulkinnan jälkeen tulee omaksua tulokset. Toisin sanoin täytyy ymmärtää mitä tämä tarkoittaa käytännössä.
Omaksuminen poikkeaa myös datankeräysmenetelmän mukaan. Mikäli kysymyksessä on tuotantodata – havaintodata – sen syntymekanismia voidaan selvittä välittömästi analyysin ja tulkinnan jälkeen.
Mikäli kysymyksessä on kokeellinen data, tulee suorittaa päättely, mitä tämä käytännössä tarkoittaa. On aina olemassa ero tilastollisesti merkittävän ja ekonomisesti tai eettisesti merkittävän eron välillä.
Kuvassa 9 on esitetty binäärinen maailma, joka normaalisti koetaan.

Ekonominen tai eettinen ero pohjautuu asiakkaan ääneen (onpa kysymys mistä tahansa sidosryhmästä) – VOC, eli Voice of the Customers. Asiakkaan ääni kuvataan käytännössä suunniteltuna rajana – speksinä. Tämä speksi voi kokeellisessa tutkimuksessa olla päätös siitä, onko löydetty tarpeeksi tilastollisesti merkittävä tekijä, joka vaikuttaa tuloksiin ja saavutettu ihmisen asettama mielikuvituksellinen tavoite (speksi).
Seuraavassa artikkelissa jatketaan aihetta. Aiheena on mitä on todella löydetty, ja mitä ei, vertailun ja signaalin suodatuksen avulla. Jos analysoit oikein, tulkitset oikein, mutta jostain syytä et pääse haluttuun tulokseen, missä vika?
Koko artikkelisarja:
Osa I: käsittelee datan laatua ja laatuteknologian rooli datan laadun parantamisessa, 27.1.2009
Osa II: käsittelee datan analyysiä; signaali vs. kohina, 13.2.2009
Osa III: käsittelee datan keräystä ja signaalityyppejä, 11.3.2009
Osa IV: 14.4.2009


Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.